Dzisiejsza publikacja w Gazecie Wyborczej „Sondaż obywatelski jak lodowaty prysznic” wzbudzi zapewne spory odzew wśród polityków i komentatorów, jak to się mówi namiesza. Ja się odniosę jednak do kwestii technicznej, która jest tu jednak źle, medialnie mocno przedstawiana.
W nagłówkach czytamy o próbie liczącej 4 tys. respondentów, czyli bardzo dużej w zestawieniu z normalnymi sondażami robionymi na próbach około tysiąca osób. I dopiero gdzieś w tekście, trochę z boku (oraz w podpisach wykresów, ciekawe kto je czyta?) stoi napisane, że o wariant każdej konfiguracji opozycji pytano osobno. A to zmienia diametralnie obraz sytuacji. Bo próba 4 tys. a cztery próby po 1 tys. to zupełnie nieporównywalne badania.
Błąd losowy na próbie czterokrotnie liczniejszej jest mniejszy, oczywiście nie 4 razy ale tylko 2 razy (na błąd wpływa nie liczebność próby a pierwiastek z liczebności próby, napisałem o tym wcześniej w jednej z notek). Ale tu mamy cztery osobne próby, osobno badane na innym kwestionariuszu i każda ma swój osobny błąd.
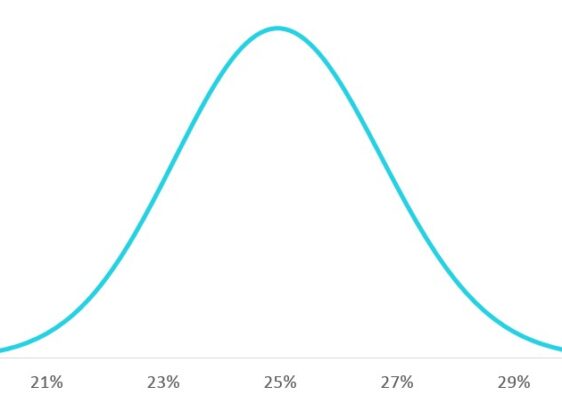
Tu na chwilę o wielkości tego błędu, często w publikacjach pisze się przy takich okazjach o błędzie (często dodając „maksymalnym”) na poziomie 3 punktów procentowych. A tak wcale nie jest, ponieważ o zasadniczą rzecz, a mianowicie o poparcie danej listy pyta się tylko zdecydowanych głosować (wyraźnie jest i tu w tekście), a tych jest ok. 600. Tak więc poziom błędu jest znacząco większy niż te 3 punkty procentowe, w zależności od poziomu poparcia ugrupowania od trochę poniżej 3 przy kilkunastoprocentowym do 4 punktów procentowych dla poparcia rzędu 50%.
Tak więc w badaniu nie mamy do czynienia z błędem na poziomie jednego, dwóch punktów procentowych gdyby próba była jedna duża, ale z osobnymi błędami rzędu 2.5-4 punkty procentowe dla każdej z czterech prób. I nie ma tu znaczenia fakt, że były losowane razem.

Oczywiście sam fakt, że badanie przeprowadzono jednocześnie (okres tylko dla badania bardzo niedobry, mocno wzburzone nastroje po śmierci syna posłanki i po rozpętanej awanturze o Jana Pawła II) i tą samą metodologią redukuje wpływ innych błędów dla porównywalności wyników. Jak najbardziej mogą być ze sobą zestawiane i obraz będzie prawdziwszy niż dla porównywania badań robionych w innych okresach, przez różne firmy, czy przy różnie formułowanych pytaniach. Szkoda tylko, że na sam koniec badania nie zadano jednak dodatkowych pytań o inne konfiguracje.
Niemniej interpretując wyniki musimy mieć na uwadze, że zestawiając wyniki każdych dwóch zaprezentowanych sondaży, każdy z nich z osobna może mieć inne odchylenie od rzeczywistego wyniku, zarówno co do wielkości jak i kierunku błędu.
A tak swoją drogą przypomniała mi się scena z Killera i dwa tysiące pesos. Wiem, zgryźliwa maruda jestem.
A moje rachunki wg podanych w tekście sondaży dają następujące liczby mandatów:
Wariant A. Cztery listy opozycji
PiS 194 KO 140 Lewica 44 PSL 0 Konfederacja 51 PL2050 30 MN 1
Wariant B. blok „KO + Lewica” oraz blok „PL2050 + PSL”
PiS 205 KO+Lewica 153 PSL+PL2050 51 Konfederacja 50 MN 1
Wariant C. KO startuje z Polską 2050 i PSL, Lewica osobno
PiS 189 KO+PSL+PL2050 174 Lewica 36 Konfederacja 60 MN 1
Wariant D. Wspólna lista całej opozycji
PiS 172 KO+Lewica+PSL+PL2050 240 Konfederacja 47 MN 1